

Als je twee mensen dezelfde data laat analyseren, komen ze dan met dezelfde conclusies? En zo niet, hoeveel waarde moet je dan aan een data-analyse hechten? Kortom, hoe objectief is een data-analyse?
Meten wat je wilt meten
Een vraag met data beantwoorden is niet altijd eenduidig. Eén van mijn eerdere blogs schreef ik rond de vraag hoe spannend de Champions League nog is (antwoord: in elk geval niet veel minder dan vroeger). Cijfers zijn hier snel gevonden in de vorm van een bestand met uitslagen van alle wedstrijden van eerdere edities. Maar wat is spanning precies, en hoe meet je dat?
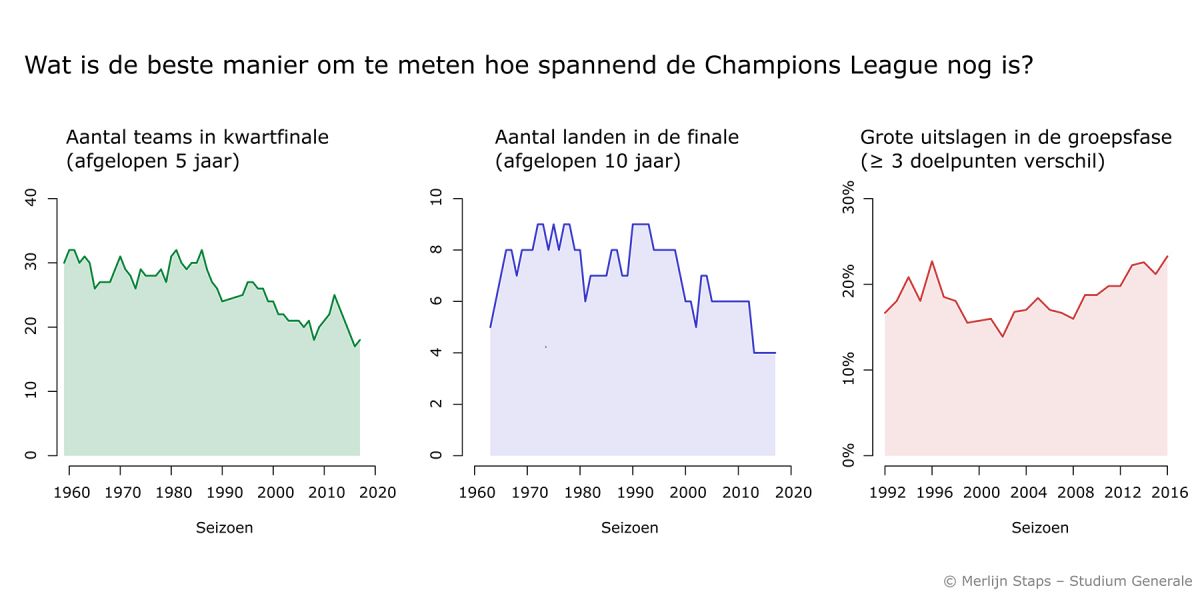
Bovenstaande figuur laat drie opties zien. Je kunt kijken naar de teams die doordringen tot de laatste fase van het toernooi. Zijn dat elk jaar dezelfde (saai!) of juist telkens andere (spannend!). Je zou ook een grafiek kunnen maken die laat zien dat de afgelopen jaren alleen teams uit de vier grote voetballanden (Spanje, Engeland, Italië, Duitsland) nog de finale halen. Dat was vroeger wel anders. Of je kunt kijken naar welk percentage wedstrijden in een grote uitslag eindigt. Een groepsfase waarin de helft van de wedstrijden in 3-0 (of erger) eindigt, is niet interessant.
Dezelfde vraag kun je dus op meerdere manieren met data proberen te beantwoorden. Ik koos uiteindelijk voor de eerste optie, omdat ik vond dat dat het dichtst in de buurt kwam bij waar ik in geïnteresseerd was.
Eén dataset, meerdere conclusies
De Amerikaanse psycholoog Brian Nosek wilde weten hoe ver de uitkomsten van verschillende data-analyses uit elkaar liggen. Hij vroeg 29 onderzoeksteams te onderzoeken of zwarte voetballers sneller een rode kaart krijgen. Alle teams kregen dezelfde dataset, maar mochten zelf een analysemethode kiezen.

Sommige onderzoekers concludeerden dat er geen verschil was tussen zwarte en witte voetballers. Anderen concludeerden dat een rode kaart voor een zwarte speler drie keer zo waarschijnlijk was als voor een witte speler. Van de 29 teams vonden er 8 geen significant verschil; de andere 21 vonden dat zwarte spelers sneller een rode kaart kregen. Maar hoeveel waarschijnlijker het was voor een zwarte speler om een rode kaart te krijgen, daar waren ze het niet over eens.
Wie had er nu gelijk? Dat verschillende onderzoekers met een ander antwoord kwamen, komt niet doordat sommigen zich vergist hadden. De oorzaak was dat ze andere – nog steeds verdedigbare – keuzes maakten bij het analyseren van de data. Is het bijvoorbeeld zo dat sommige clubs meer rode kaarten krijgen dan andere (vanwege hun agressievere speelstijl), en zou je daarvoor moeten corrigeren? Wat daar het beste is, is moeilijk te zeggen.
Dat je bij dezelfde data verschillende conclusies kunt trekken, kwam ik in mijn blogserie zelf ook tegen.
Case study: het eurovisiesongfestival
In het eerste blog van deze serie analyseerde ik het stemgedrag bij het Eurovisiesongfestival. Hoe groot is de rol van vriendjespolitiek? Ik was niet de eerste die hiernaar keek – er zijn zelfs wetenschappelijke papers over geschreven. Wijkt de uitkomst van mijn analyse af van die van anderen?
De auteur van de dataset die ik gebruikte, Stephan Okhuijsen, vond net als ik dat landen bij elkaar in de buurt elkaar hogere scores geven. Informaticus Tim Cocx van de Universiteit Leiden vond in 2005 net als ik bewijs voor 'asymmetrische' relaties waarin bijvoorbeeld Monaco wel punten geeft aan Frankrijk, maar niet andersom. Daar vond ik weinig bewijs voor. Michiel Vellekoop en Laura Spierdijk van de Universiteit Twente vonden ook bewijs voor vriendjespolitiek, maar wezen naar de Baltische staten als de grootste boosdoeners. Ik juist naar de duo's Roemenië-Moldavië, en Griekenland-Cyprus.
Net als bij het rode-kaartenexperiment geldt bij het songfestival ook dat geen twee analyses tot precies dezelfde conclusie komen.
De juiste analyse kiezen
Wat er uit een data-analyse komt hangt dus sterk af van hoe je de data analyseert. Dat kan op meerdere manieren, zonder dat de ene 'goed' is en de ander 'fout'. Een keuze maken kan lastig zijn. Het gevaar is dat je je gaat laten leiden door hoe de data er uit komen te zien en welk verhaal je dan kunt vertellen.
Als je een data-analyse te zien krijgt, zie je meestal niet hoe die tot stand is gekomen en weet je niet tot in detail welke keuzes de maker heeft gemaakt. Dat is ook niet van levensbelang, want uiteindelijk is overal wel wat op af te dingen. Maar dat een volgende analyse weer met een ander verhaal kan komen, is grond voor scepticisme.

Moet je een data-analyse geloven?
Er is ook goed nieuws. Hoewel verschillende analyses op specifieke punten verschillen, blijven de grote lijnen overeind staan. Bij het rode-kaartenexperiment was er consensus dat zwarte spelers eerder uit het veld werden gestuurd. Bij het songfestival was er niemand die concludeerde dat er helemaal geen vriendjespolitiek was. Daarentegen kun je al te specifieke conclusies (zoals “zwarte spelers krijgen twee keer zo snel een rode kaart als witte spelers” of “Griekenland en Cyprus zijn de dikste vrienden op het songfestival”) maar beter met een korreltje zout nemen, want die kunnen heel gevoelig zijn voor hoe de data precies geanalyseerd zijn.
Denk de volgende keer dat je een analyse van een dataset, een grafiek of statistieken ziet aan foto's van de Domtoren. Daar zijn er duizenden van gemaakt, maar geen twee foto's zijn precies hetzelfde. Verschillende foto's zullen uit verschillende hoeken genomen zijn en andere kanten van de Dom belichten of genomen zijn in andere lichtomstandigheden. Hoe meer foto's je te zien krijgt, hoe waarheidsgetrouwer je beeld van de toren wordt. Met data werkt het hetzelfde. Een data-analyse is geen wiskundige berekening waarbij de uitkomst elke keer hetzelfde is. Een enkele foto kan een vertekenend beeld geven van het geheel, maar dat kun je aan die ene foto niet zien.
Data in beeld
Dit blog is onderdeel van de serie "Data in beeld" waarin stagiair Merlijn Staps gebruik maakt van data om populaire ideeën tegen het licht te houden. Wat kunnen we leren van statistieken? En bevestigen de cijfers onze intuïtie of juist niet? Lees ook de andere blogs.


